Deep Blue Data Glossary
In this glossary, we define how we use the following terms in Deep Blue Data. The first section of the glossary ("Works and their components") describes the pieces of a "Work," and the second section ("Important terms") describes other useful words and concepts for using Deep Blue Data.
 />
/>
Works and their components
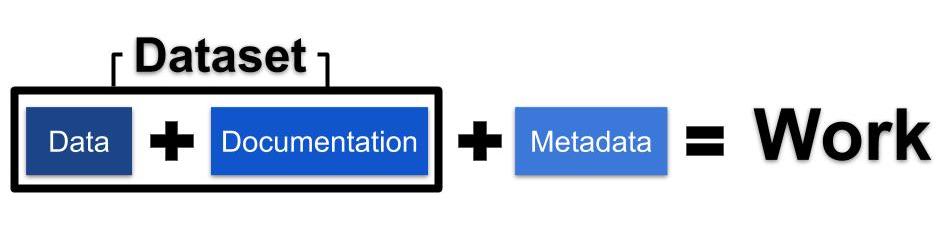
Dataset: A dataset includes all files or documents that contain research data, as well as any additional components providing information on how to access or understand those files’ contents, such as documentation.
Documentation: The information needed for people to understand, trust, and use a dataset. Documentation expands upon the information provided in a dataset’s metadata, providing further details about how the data were collected, processed, and analyzed.
Documentation can come in many forms. Some researchers create README documents (often a plain text file or PDF) or codebooks as separate files, which then become a part of the dataset. In other cases, documentation may be embedded within data files themselves; examples include a separate sheet in a Microsoft Excel file defining unfamiliar terms and variables, or commented lines in a code file that explain decision points or algorithms. Every dataset can benefit from some form of documentation. For further explanation, recommendations, and resources, read the documentation guidance provided in Deep Blue Data’s Depositor Guide.
Metadata: Descriptive information that defines key attributes about a dataset. When researchers create metadata for their datasets, others in their community of practice can more easily discover the data and assess its relevance to their work. As metadata are designed to be discoverable through online search engines, researchers preparing metadata should consider what details others will need to find and connect with the dataset.
Research data: Any data produced during the process of research in any discipline. This includes representations of observations, objects, or other entities used as evidence of phenomena for the purposes of research or scholarship.
Work: The main organizational unit in the Deep Blue Data repository, generally represented as a web page. When you deposit data, documentation, and metadata, those combined pieces form a Work, which together will appear as the publicly available dataset.
Other useful terms
Administrative data: Data collected and used for the purpose of administrative activities. As a research data repository, we generally do not accept this kind of data. Our goal is to host data that has been (or is being) used to create generalizable knowledge about phenomena that is applicable beyond one classroom, office, or institution.
Bit-level preservation: All digital files are, at their most basic level, a sequence of bits (1’s and 0’s) encoded in physical material like a hard drive. When Deep Blue Data ingests a new file, our system automatically preserves the file’s sequence of bits (or "bitstream"), no matter the file type. "Bit-level preservation" means that we keep this bitstream for reference so that we can a) regularly check that files have not mutated over time as a result of things like bit-rot, and b) restore files that have undergone changes if necessary.
Bit-rot: A change in a bitstream as a result of physical wear-and-tear on the material on which it is written. Thanks to advances in technology, bit-rot is much rarer and less severe than it used to be. However, at Deep Blue Data, we take bit-rot seriously by storing file copies on multiple servers and checking regularly to see if it has occurred.
Checksum: A handy algorithm for detecting even the smallest differences between files. We can immediately see if a file has changed by comparing its current checksum to the checksum our system generated when the file was first uploaded; we can then restore the file to its original state if need be.
Collection: A grouping of Works in the Deep Blue Data repository. These groupings can be used by researchers or Deep Blue Data staff to group related Works for ease of navigation. If you are interested in creating a Collection, please contact us. Examples of our collections include:
- Central Mali geography photos
- Neighborhood Effects: Community Characteristics and Health in Metropolitan Detroit
DOI: A unique, permanent digital code assigned to an object. DOI stands for Digital Object Identifier. DOIs are commonly used in academia to identify scholarly works and can be connected to metadata and URLs that point to an object’s online location or representation. As part of its mission to encourage data sharing and elevate research data as valuable scholarly output, Deep Blue Data works with DataCite, a DOI Registration Agency, to mint DOIs for datasets deposited to Deep Blue Data. For a more detailed discussion of DOIs for datasets, visit DataCite’s website.
Fixity: The state of being unchanged over time. Deep Blue Data ensures fixity for the files it hosts; in other words, we ensure that all files are continually fixed in the exact same state they were in upon upload, without a bit out of place.
Open access: A publishing model that seeks to make scholarly output, which is often indirectly paid for by tax dollars, freely and readily available to the public. As an Open Access repository, Deep Blue Data allows anyone with access to the internet to view Works and download files. Allowed uses of those files are governed by the license selected by the depositor and Deep Blue Data’s Terms of Use.
Open format: A file format with publicly available documentation or specifications. These files can be opened with a variety of software and hardware systems and are often associated with widely accepted professional standards. Quintessential examples are Plain Text (.txt) and Comma Separated Values (.csv) files. Deep Blue Data can provide superior preservation services for open formats as compared with proprietary formats.
Proprietary format: A file format that is commercially developed, which often means that its specifications are not publicly available and/or that files in that format can only be used with specialized software or hardware. Though Deep Blue Data accepts files in all formats, the repository’s ability to preserve proprietary formats is limited; therefore, files in open formats are preferred. For more details about Deep Blue Data’s Preservation Policy, visit the Policies and Terms of Use page.
Proxy: A person to whom a depositor gives the authority to make a deposit on the depositor’s behalf. In cases where a proxy is appointed, the depositor of record still retains the authority to alter the deposit and answer questions about it; they remain responsible for its content.
Personally identifiable information: Data that can be used to discover the identity of human research subjects is considered to be personally identifiable information. In the vast majority of cases, we do not accept this kind of data, for both legal and ethical reasons. For more information, feel free to review U-M’s standard practice guide for research with human participants.
Sensitive data: Data that, if published, could result in harm to research subjects through the disclosure of information that is considered confidential or private. Deep Blue Data does not accept sensitive data. However, in some cases, data can be de-identified or otherwise modified to allow publication. Researchers with questions or concerns about the sensitivity of their data should reach out to Research Ethics and Compliance, a unit of the University of Michigan’s Office of Research.