Depositor Guide
We welcome your deposit to Deep Blue Data, and the opportunity to partner with you as a host for your work.
It is possible to simply click "Deposit Your Work” on the Deep Blue Data home page and follow the instructions from there; however, to ensure that your work is as accessible, reusable, and preservable as possible, we recommend that you follow this guide closely. Feel free to consult our glossary if you have questions about our terminology.
Before making a deposit in Deep Blue Data, you should ask yourself, "Is my work eligible to be hosted in Deep Blue Data?" We accept eligible research data from a wide variety of disciplines. For more information on the data types we can and cannot accept, please review our Policies and Terms of Use. Please contact us with any questions you have.
The deposit process follows 4 broad steps:
- Preparing data
- Preparing documentation
- Depositing in Deep Blue Data
- Reviewing and incorporating feedback
Step 1: Preparing Data
Before you begin your deposit, please ensure that your data are:
- Complete – Any data submitted to Deep Blue Data should encompass the full results of a completed project, or a discrete part of a project that can be interpreted in its own right. There should be no further need to add, clean, or manipulate the final version of the data you submit. However, we do encourage you to consider including "raw" as well as processed iterations of the data. As a part of ensuring that data can be interpreted by others, please include any documentation required to understand and reuse data, including information about how the data were processed and analyzed (this includes any data-cleaning code).
- Preservable – Deep Blue Data will accept any file format. However, whenever possible, we ask that you submit data in a preservation-friendly format, so that interested users can access your data in the long term regardless of changes in software.
- Openly distributable and ready for reuse – Data in Deep Blue Data are openly available to anyone to study and reuse, and should have no restrictions attached. If your data are complete, ethical, and preservable (as defined above), they are typically ready for distribution and reuse; however, please carefully check that there are no other factors that prevent your data from being shared in this way. For more information see our Policies.
- Ethical – Before submitting, please ensure that your data do not contain any information that could be used to personally identify and/or harm human or other subjects, and that no data contain any personal information outside what any human subject agreed to share when consenting to participate in your research. If you have one, please include the IRB approved consent form for your study with your deposit.
For more information on what kinds of data we can and cannot accept, please review our Policies. We also encourage you to check out other resources for more information on preparation of data deposit, such as:
- The Inter-university Consortium for Political and Social Research (ICPSR)’s guide to preparing data for sharing
- The USGS web page on Data Release
Which file formats are most preservation-friendly?
Some file formats are easier to preserve long-term than others, and the level of preservation that Deep Blue Data can provide depends on the file format in which you submit your data.
| Level | Eligible file formats | What we do |
|---|---|---|
| 1 (Highest) | Formats that are both publicly documented and widely used (example: CSV). | We will make our best effort to preserve the file’s content, structure and functionality. The content may be migrated to another stable format if necessary for its preservation. |
| 2 (Limited) | Proprietary formats that are widely used and where there is substantial commercial interest in maintaining access to the format (example: Microsoft Excel). | We will make limited efforts to maintain the usability of the file as well as preserving it as submitted (bit-level preservation). |
| 3 (Basic) | Highly specialized proprietary formats, often usable only in a single software environment; formats no longer widely utilized; and/or formats about which little information is publicly available. | We provide basic preservation of the file (bitstream only, with no active effort to monitor or migrate the format). As software environments change over time, we cannot guarantee that content, structure, or functionality will be preserved. |
See our Preservation Policy for more details.
In addition to the recommendations in the Library’s Registered Formats and Support Levels (PDF), we have the following data type-specific recommendations:
Tabular – CSV. While CSV files do not support formulas like Excel files do, they are much easier to preserve in the long term because of their relative simplicity and open format. If you feel that an Excel file (or other tabular data in a proprietary format) is still the best representation of your work, we recommend that you submit your data as both an Excel file and a CSV file.
Compressed files – Compression (.zip, .gz, tar.gz) may be used for deposits that require a specific file structure, though it can introduce preservation challenges. ZIP or tar files are only as good as their contents. If you are using a Mac computer, we recommend compressing with The Unarchiver or p7zip (command line only); Mac’s built-in "Compressor/Archive Utility" has issues with creating openable compressed files larger than 4 GB.
Code – While we do not recommend a specific file format, we advise you to include information about your programming environment and versioning in your documentation. If you use any code libraries beyond your base language, please include version information for those as well (for example "The code in mydata.py was written in VSCode version 1.42.0 in a MacOS Catalina 10.15.3 environment with Python version 3.7.4; data were analyzed with Pandas version 1.0.0; data were visualized with Seaborn version 0.10.0"). If your code was created with proprietary software, we suggest that that you include information on how best to run it with comparable open source software.
3-D images – Though we recommend no specific file format, as with code, the more comprehensive information you provide about the environment in which you created your images, the easier it will be for future users to access your data as you originally intended.
Human Data Guidelines
Data involving humans will be subject to additional review during the curation process to ensure that it is appropriate for public sharing, whether or not it was subject to the oversight of an Institutional Review Board (IRB). If you are uploading data that involves humans:
- You are required to provide a blank copy of the consent form, information sheet, or other participant agreement as part of the documentation for the deposit (ideally to be published alongside the data).
- A Deep Blue Data curator will evaluate the submission for the following criteria:
- The dataset meets the Low Sensitivity classification as defined by U-M Data Classification Levels. This requires that any data about humans has been de-identified by removing direct identifiers. (See pages 2 and 3 of Dryad's Best Practices: Sharing Human Subjects Data for examples of direct and indirect identifiers).
- The dataset does not violate the US Department of Justice’s Bulk Sensitive Data Regulations on sharing sensitive personal or government-related data. This includes but isn’t limited to:
- Human genomic data concerning over 100 U.S. persons and other covered categories of human genomic data on over 1,000 U.S. persons.
- Biometric identifiers concerning over 1,000 U.S. persons.
- Precise geolocation data concerning over 1,000 U.S. devices.
- Personal health data and personal financial data concerning over 10,000 U.S. persons.
- Specific personal identifiers concerning over 100,000 U.S. persons.
- The consent form, information sheet, or other participant agreement does not contain any language that precludes sharing data publicly. Examples of restrictive language include (but aren’t limited to):
- "Data will only be shared in aggregate" (if data is at an individual level.)
- "Data will only be shared with other researchers."
- “Data will be destroyed.”
- See also ICPSR’s Recommended Informed Consent Language for Data Sharing and RDSI’s Bulletins on Informed Consent & Data Sharing, and De-identifying Data for other known concerns and recommended alternatives.
- The consent form, information sheet, or other participant agreement should state that data will be shared at the individual level, if applicable, and that data will be shared publicly (anyone on the Internet can access the data). Language should be specific (e.g, “de-identified data” vs. “records”) and used consistently throughout the document.
- In cases where Deep Blue Data staff cannot determine that data is sufficiently de-identified, or participants’ consent to publicly share the specific data concerned is not sufficiently documented, Deep Blue Data staff may:
- require additional documentation that researchers adhered to ethical best practices in their field.
- make further de-identification recommendations, including the removal of indirect identifiers.
- consult other resources or experts, or refer the depositor(s) to another office with expertise (i.e., IRB or DOCTR), to help clarify whether documentation is sufficient.
- suggest another repository that provides controlled access to datasets.
- withdraw the dataset and decline to publish it.
- If you wish, you may contact us when writing your consent form, information sheet, or other participant agreement and we will be happy to consult on appropriate data sharing language for deposit into Deep Blue Data.
Step 2: Preparing Documentation
Provide future users of your data with the information they need to understand your data and use it in their own work.
To find, understand, trust, and make use of your data, researchers need more than the data files. They need documentation as well. The best documentation is often a simple text file that includes a detailed explanation of the context in which the dataset was created; the methods used to collect, process, and analyze the data; and what the values and terms in the data signify. (Even when information is provided in a research publication about your data, research publications often leave out key details about the data itself, and interested users may not be able to access it, because unlike Deep Blue Data, many publications are restricted behind a paywall.)
Comprehensive documentation also makes your data more discoverable. There are well-established paths for discovering publications like journal articles or book chapters; however, this is not the case for many other types of scholarship. The stronger your documentation is, the stronger your dataset will be! (At Deep Blue Data, we use "dataset" to refer to the combined unit of your data and your documentation. See our glossary for more details.)
Though practices and needs for describing research data will be determined on a case by case basis, the following areas should be covered at minimum in documentation:
- Research Overview – A summary of the subject and purpose of the research, as well as who conducted the research, where and when it took place, and the research funding sources.
- Methods – An account of how the research was conducted, with a focus on how data were collected, processed, and analyzed. Sampling procedures, instruments, and software used should be described to convey how data were produced and transformed.
- File Inventory – A list of each of the files included in the data, including a brief statement of what each file contains and its purpose. An explanation of the organization of the files, including relationships between files, should be considered for inclusion as well.
- Definition of Terms and Variables – A glossary or set of in-text descriptions that clearly specifies the meaning of ambiguous terms, obscure procedures, variables, and/or units that appear throughout the dataset (without jargon). This may take the form of a list of definitions, a data dictionary in a spreadsheet, or comment lines distributed through a program.
- Use and Access – Instructions on how to open, run or make use of the files (if needed).
- Informed consent – If your data are the product of research in which subjects underwent a consent process, please include a blank copy of the informed consent form and/or terms of consent as part of your documentation.
Follow this link for an example readme that you can adapt if you wish. If you have questions about how best to document your research process, feel free to contact us; we are happy to brainstorm best practices with you.
Step 3: Depositing in Deep Blue Data
Supply metadata (including license); upload data and documentation.
Now that you have a complete dataset with both data and documentation, you are ready to submit your work! (At Deep Blue Data, we use "dataset" to refer to the combined unit of your data and your documentation, and "work" to refer to the combined unit of your dataset and your metadata. See our glossary for more details.)
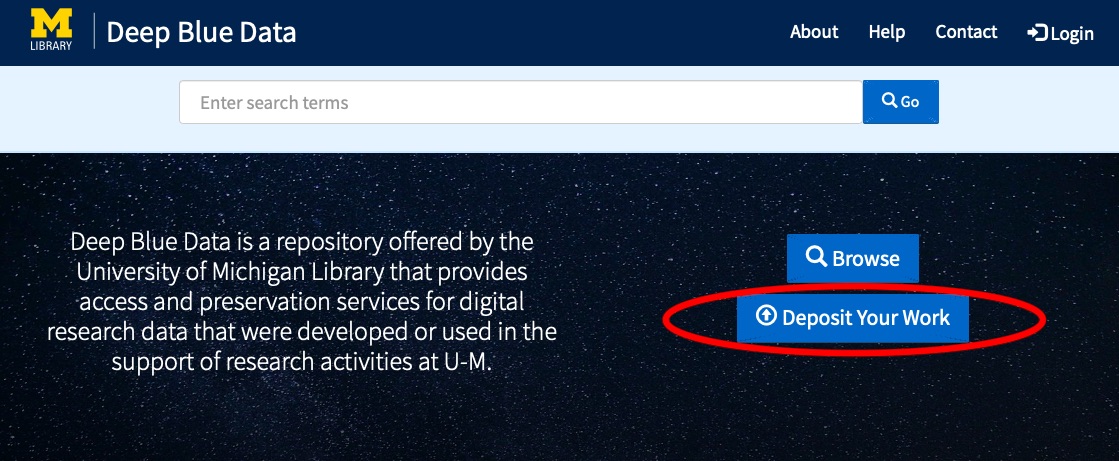
Navigate to our home page and click "Deposit Your Work" to get started.
Create metadata
Under the "Descriptions" tab, you will need to provide metadata, which will help people who may be interested in the dataset to find it and understand it well enough to decide whether or not they would like to download it from Deep Blue Data. Metadata is different from documentation, such as readme files, field notes or codebooks. Although they serve similar functions of providing important information about a dataset, metadata is generally more brief and succinct than documentation; it’s the first thing that someone sees when they encounter your dataset in Deep Blue Data.
Here are more detailed instructions on completing the metadata fields in the "Deposit Your Work" form on Deep Blue Data For an example of a record that provides a good example for most metadata, see Dataset of live-cell movies of single PolC-PAmCherry molecules in Bacillus subtilis cells with high and low fluorescent backgrounds.
Title – Create a Title that will allow users to discover and understand the purpose of your dataset. The best titles are:
- Accessible – Use clear language and avoid jargon that will not be immediately recognizable to those within your field.
- Concise - The title should be clear and descriptive, but not longer than absolutely necessary.
- Descriptive – The title will be discoverable on Deep Blue Data and through other search engines. Consider mentioning the general area of research and/or the specific topic in the title.
- Unique – Your dataset is a discrete research product that has value in and of itself, and your title should reflect that even if your dataset is also incorporated into a broader project. Consider using the terms "data" or "dataset" or referencing specific methods to help distinguish the dataset from other research products.
ORCID iD – If you'd like your ORCID iD to appear in the metadata, follow instructions on the Connect your ORCID page.
Creator – List the name(s) of the person(s) and/or organization(s) responsible for creating the Work. For names, please use the following format: Last name, First name Middle Initial. If the dataset has more than one creator, they should each be listed in separate Creator fields.
Contact Information – Enter the email address for the individual who can best respond to questions about the work. Contact information will be invaluable to other researchers if they need additional information or guidance when re-using the data or reproducing the research.
Methodology – Explain the methods that were used to collect and process the data included in this Work. This could include:
- Specific data collection methods (e.g. content analysis, experiment, observation, simulation, survey, etc.) and details on how they were employed.
- Tools used to collect, process, and/or analyze the data (i.e. names and versions of software, instruments, statistical tests, etc.).
This information may take a few sentences or a paragraph to explain adequately. Anything more than a paragraph is probably too long for the metadata, and a full accounting of the methods used to collect, process and analyze the data can be saved for the documentation.
Description – Provide a general and brief description of the research that produced this data, including the researchers’ purpose or questions they wanted to answer. Though related to the "Methodology" field, the "Description" field should cover more generally what the data are and the overall research context, rather than specifics of how the dataset came to be.
Date Coverage – Select the span of time that the data represent or the dates the data were collected, whichever is more salient for your data. Please also indicate what the chosen dates represent in your readme.
License – Select a licensing and distribution option that will govern use of the Work. Your choice will let users know if and under what conditions they can share and re-use the included data without requesting further permissions. For more information about which licenses to select, see our Deposit Policy.
Discipline – Select the discipline(s) associated with the research for which the data were collected.
Funding Agency – If applicable, select the primary funding agency that supported the research project for which the data were generated or collected. If the funding agency for your dataset is not represented in the drop-down, select the "Other Funding Agency" option and enter the funding agency name in the specified field.
ORSP Grant Number – If applicable, enter the PAF number assigned by the University of Michigan’s Office of Research and Sponsored Projects (ORSP).
Keyword – Enter any terms or topics that describe your work or would help people to find it in Deep Blue Data. Keywords may include the following:
- Disciplines or sub-disciplines
- Research topics or areas
- Methods or tools central to the research
- Time periods and/or locations associated with the data
We encourage you to add multiple keywords by clicking "+ Add another Keyword" below the Keyword text box.
Language – List the language(s) in which the data and supplementary content are written. These could be spoken languages (e.g. English, Spanish, Mandarin, Arabic, etc.) or programming languages (e.g. C++, MATLAB, Python, XML, etc.).
Citation to related material – Enter a citation to any publication(s) that make use of or reference the data in this Work. Most often, these will be articles and books by the Creator(s) or the research group.
Include a full citation where possible, including a link to a URL, DOI, or unique identifier for the related item. If the publication has not yet been released, please provide a "forthcoming," "in-press," etc. interim citation and plan to contact us with an updated citation once it has been published.
Related items in Deep Blue Documents – If the article(s) accompanying your dataset are available in our document repository Deep Blue Documents, enter the citation(s) for the record(s) here. If you have questions about depositing your article(s) in Deep Blue Documents, please contact us.
Upload data and documentation files
For the next step, click on the "Files" tab to the right of the "Description" tab near the top of the page. At present, we accept deposits of any size. However, be mindful that the size of your dataset does impact the ways you can upload it to Deep Blue Data.
If your full dataset is:
- Up to 5 GB – you can submit your dataset directly through the Deep Blue Data online interface. There is no limit on the number of deposits that can be submitted through self-service.
- 5 GB or greater and/or more than 100 files – you will need to contact Deep Blue Data to facilitate your deposit – we will be happy to help you upload your dataset. Please submit your metadata without files for the time being! This will create a draft page in Deep Blue Data where our team can upload and review your files.
Regardless of your file size or number of files, we are committed to helping you share your dataset as efficiently as possible. Be mindful that single files or aggregations of files exceeding 1 TB may pose challenges based on the underlying Deep Blue Data repository software. In such cases, we are happy to work with you to assess how your work can best be shared. For more information, feel free to consult our Submission and Deposit Policy.
In addition to your data files, please upload the documentation you prepared.
Choose visibility (Open Access or Embargo)
Congratulations! Your dataset is now a Work, consisting of metadata and files, in Deep Blue Data.
We recognize that situations exist in which you won't want to offer immediate access to your Work. Notwithstanding legal requirements the University is bound to honor (such as FOIA requests), you can embargo your Work in Deep Blue Data for up to a year. (If you have questions about restricting specific files, contact us).
- Open Access – Publicly available immediately following DBD staff approval.
- Embargo – Set date for future public release (following DBD staff approval).
Step 4: Reviewing and incorporating feedback
You will receive correspondence from Deep Blue Data and staff following your deposit. Please look for and respond to the following:
Upon deposit – You will receive an email confirming the creation of your deposit, and another email confirming the files you have uploaded (use this manifest to make sure everything you intended to upload is included in the deposit).
1-2 days after deposit – For each deposit, we perform an initial review within the first day or two. We confirm that the deposit meets our acceptance criteria, contains both data and accompanying documentation, and that all files have successfully been ingested and can be downloaded and opened. At this time, we may contact you by email to let you know if we need more information to proceed. If you need a DOI prior to publishing your dataset but after uploading files, we are happy to provide that for you; please contact us at any time to request this.
1-2 weeks after deposit – We review the deposit fully (sometimes bringing in the appropriate subject librarian or another expert) for completeness and legibility of metadata, documentation and data. We then send any curation recommendations to you and work with them to make changes to the record. The entire process usually takes a few days to a few weeks, depending on the state of the dataset and the depositor’s timeline for publication. Please contact us if you need to arrange for an expedited review and we will do our best to accomodate you.
Our goal is for Deep Blue Data to serve as a means for datasets of interest to be discovered, understood and used by others in ways that benefit you, the dataset creator, and our feedback is intended to make your work as accessible, reusable, and preservable as possible. We understand that people may face deadlines or other time constraints in publishing data.
After you review and incorporate feedback – Once we have worked with you to resolve any recommended changes for the dataset, we will publish your Work on Deep Blue Data. At this point, the Work is an active part of the scholarly record, just as a published journal article would be. Modifications to the work are discouraged unless absolutely necessary. In the event that you believe your dataset or metadata needs to be updated, please contact us.
To learn more about how we will preserve your data over time, see our Preservation Policy.